ANÁLISIS Y DISEÑO DE EXPERIMENTOS APLICADOS A ESTUDIOS DE SIMULACIÓN
ANALYSIS AND DESIGN OF EXPERIMENTS APPLIED TO SIMULATION STUDIES
JUAN CARLOS
SALAZAR
Profesor Asociado , Escuela
de Estadística, Universidad Nacional de Colombia,, jcsalaza@unalmed.edu.co
ARMANDO
BAENA ZAPATA
Profesor, Escuela de
Microbiología, Grupo Infección y Cáncer, Universidad de Antioquia, arbaza@udea.edu.co
Recibido para revisar julio 25 de 2008, aceptado octubre 28 de 2008, versión final noviembre 20 de 2008
RESUMEN: Los estudios de simulación, empleados en diversas áreas de la investigación, son de gran utilidad para conocer el comportamiento de ciertos fenómenos bajo diferentes escenarios virtuales propiciados por el investigador a través de algún software especializado. En el campo de la estadística son muy comunes los estudios de robustez, muchos de ellos utilizados para observar el comportamiento de un estimador ante diferentes situaciones hipotéticas que pudieran presentarse en la realidad. Dada la semejanza entre los estudios de simulación y los estudios experimentales, el objetivo de este trabajo es proponer el uso de la metodología y del diseño y análisis de experimentos en los estudios de simulación. Se presenta como ejemplo el estudio de simulación Robustez de un modelo de Markov de tres estados bajo distintas especificaciones distribucionales de los tiempos de transición realizado bajo el enfoque del diseño experimental y utilizando el análisis de varianza y la regresión múltiple con el fin de probar el efecto del tamaño muestral, el máximo número de visitas y el tipo de distribución de los tiempos de transición sobre la estimación de los parámetros del modelo markoviano de tres estados.
PALABRAS CLAVE: Estudios de Simulación, Diseño de Experimentos, Modelos Lineales Generalizados, Procesos Estocásticos.
ABSTRACT: Simulation studies, when used in several areas of investigation, are quite useful to study the behavior of some phenomena in which different virtual situations are generated by the researcher using some specialized software. Robustness studies are rather common in statistic research; many of them are used to observe the behavior of an estimator under several hypothetical situations that could happen in practice. Due to the similarity among the studies of simulation and the experimental studies, the aim of this work is to propose the use of both the methodology and the design and analysis of experiments in the studies of simulation. As an example it is presented a simulation study called Robustness of a three-state Markov model under different distributional specifications of the transition times that was completed under the approach of the experimental design and using the analysis of variance and multiple regression model in order to prove the effect of the sample size, maximum number of visits and the type of distribution of the transition times on the estimation of the parameters in a three-state Markov model.
KEY WORDS: Simulation studies, Design of Experiments, Generalized Linear Models, Stochastic Processes.
1. INTRODUCCIÓN
Los estudios experimentales de efectos fijos son utilizados para estudiar el efecto de ciertas variables controladas por el investigador, sobre una o varias variables respuesta que representen
un fenómeno de interés. Esta metodología es la empleada para probar causalidad al fijar los niveles de las variables explicativas, en este caso llamadas factores, y evaluar los cambios
generados
sobre la(s) variable(s) respuesta(s) (ver por ejemplo [1] y [2]). A las combinaciones
de los niveles de los factores se les conoce como tratamientos. Existen
diversos tipos de diseños experimentales de efectos fijos; elegir alguno de
ellos depende de la disponibilidad de recursos tales como el tiempo [1]. Una de
las ventajas de estos estudios es que no requieren de muchas unidades
muestrales (más conocidas como unidades experimentales) o réplicas dado que la
fuente de variabilidad es controlada debido a que se garantizan las mismas
condiciones en cada corrida o ejecución del experimento y a que la asignación
de las unidades experimentales a los tratamiento es aleatoria, equilibrando los
sesgos en cada tratamiento. En total, un experimento arrojará ![]() observaciones,
donde
observaciones,
donde ![]() es el número de
tratamientos y
es el número de
tratamientos y ![]() el número de
réplicas. Las herramientas estadísticas utilizadas para analizar los datos que
resultan de un experimento son ampliamente conocidas y muchas de ellas se basan
en el análisis de varianza y en la regresión múltiple o modelo lineal general
aunque también, y de manera más amplia, en los modelos lineales generalizados;
en caso de ser necesario, es posible utilizar métodos no paramétricos
equivalentes.
el número de
réplicas. Las herramientas estadísticas utilizadas para analizar los datos que
resultan de un experimento son ampliamente conocidas y muchas de ellas se basan
en el análisis de varianza y en la regresión múltiple o modelo lineal general
aunque también, y de manera más amplia, en los modelos lineales generalizados;
en caso de ser necesario, es posible utilizar métodos no paramétricos
equivalentes.
Obsérvese que cada tratamiento conformado por la combinación de los diferentes niveles de los factores, genera un escenario en particular. Cuando dicho escenario corresponde a una situación virtual, propiciada por algún software especializado, se habla de los estudios de simulación [3]. Dichos estudios son muy comunes en la investigación estadística [4]; un ejemplo de ello es cuando se quiere estudiar el efecto del tamaño muestral en la estimación de cierto parámetro. Normalmente el análisis de los datos que resultan de un estudio de simulación se limita a la descripción de los mismos por medio de gráficos y tablas que contienen medidas de tendencia central y dispersión de la variable(s) respuesta(s) para cada uno de los diferentes escenarios simulados, sin pasar luego por un análisis inferencial. Los análisis realizados son muy descriptivos y no es común emplear técnicas inductivas para establecer diferencias significativas entre los diferentes tratamientos. Esto último le daría más fuerza al análisis y permitiría concluir con más contundencia empleando cierto nivel de significancia.
Una de las diferencias fundamentales entre este tipo de experimentos computacionales y los experimentos físicos es que en los primeros se tiene mayor control sobre los factores que inciden sobre una respuesta ya que estos factores son generados a partir de algoritmos estocásticos predefinidos cuyos parámetros son especificados por el investigador. En contraste, los experimentos físicos generan resultados que dependen de factores que frecuentemente no es posible controlar.
En el presente trabajo se presentan los pasos que comúnmente se siguen en el diseño de un experimento aplicados esta vez a un estudio de simulación. Posteriormente se ilustra como ejemplo la metodología y el análisis del estudio de simulación Robustez de un modelo de Markov de tres estados bajo distintas especificaciones distribucionales de los tiempos de transición [5]. Finalmente se ofrecen algunas conclusiones.
2. MATERIALES Y MÉTODOS
Como lo explica Montgomery en su libro de diseño de experimentos [1], para utilizar un enfoque estadístico en el diseño y análisis de un experimento es necesario que todas las personas involucradas en el proceso entiendan de qué se trata el problema, qué es lo que exactamente se va a estudiar, cómo se recolectarán los datos y tener una idea del análisis cuantitativo que se llevará a cabo. Lo mismo ocurriría en un estudio de simulación; lo más importante que hay que definir es qué se va a medir (variable(s) respuesta(s)) y en función de qué (factores y bloques). Montgomery [1] presenta en la tabla 1-1 de la página 14 una guía sencilla para diseñar un experimento. La tabla consiste en los siguientes siete pasos: 1) planteamiento del problema, 2) selección de la(s) variable(s) respuesta, 3) elección de factores y niveles, 4) elección del diseño experimental o tipo de experimento, 5) desarrollo del experimento, 6) análisis estadístico de los datos, y 7) conclusiones y recomendaciones.
Obsérvese
que el planteamiento del problema lleva a deducir cuáles variables respuesta
serán medidas, y a su vez, según la escala de estas variables, qué tipo de
análisis elegir. Los factores y sus niveles, tienen que ver también con el
planteamiento del problema ya que de éstos van a depender las variables
respuesta. La idea general es observar el comportamiento de la(s) variable(s)
respuesta en función de los factores y estimar el efecto de estos últimos sobre
la respuesta. Puede
ser útil añadir a la lista de Montgomery [1] las variables controlables y las
incontrolables. Ambas hacen referencia a variables que estarán presentes y que
probablemente afectarán a las variables respuesta. Las primeras, también
llamadas covariables, son controlables porque son plenamente identificables y
se pueden bien sea fijar (dejar constantes durante el experimento) o medir. Las
segundas son aquellas variables que no se pueden ni fijar ni medir y que se
sabe harán parte del error o sesgo. En los estudios de simulación es fácil
averiguar cuáles podrían ser las variables respuesta, los factores y las
covariables. Variables respuesta en muchos estudios de simulación podrían ser
por ejemplo el sesgo relativo, una media, una medida de dispersión o una
proporción de aciertos. Como factores se tomarían aquellas variables para las
cuales se desea ver el efecto sobre la respuesta. Ejemplos
de factores podrían ser el tipo de distribución, el tamaño de muestra, etc. En
cuanto al tipo de experimento, en términos generales se piensa en un
experimento multifactorial de efectos fijos. Es muy probable que el recurso más
importante en los estudios de simulación sea el tiempo invertido en las
corridas de las simulaciones y que esto lleve a pensar en diseños
experimentales de efectos fijos más especiales como lo son los diseños ![]() ,
, ![]() y los diseños
fraccionados; por supuesto que esto dependería del criterio del investigador.
En cualquier caso es útil presentar la caja o esquema del diseño del estudio
como se muestra en
la Figura
1.
y los diseños
fraccionados; por supuesto que esto dependería del criterio del investigador.
En cualquier caso es útil presentar la caja o esquema del diseño del estudio
como se muestra en
la Figura
1.
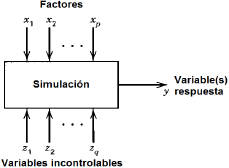
Figura 1. Esquema general de un
estudio de simulación. Adaptación del esquema de un diseño experimental presentado
en Montgomery [1]
Figure 1. General scheme of a simulation study. Adapted from a scheme presented in Montgomery [1]
Una vez estén estos aspectos claros, se procede a correr las simulaciones. Al término de éstas se construye una base de datos con los resultados y se procede al análisis estadístico. Éste comenzaría con los gráficos de cajas y bigotes y en general con el uso de todas las herramientas descriptivas que ayuden a formular posibles hipótesis que serán probadas posteriormente por medio del análisis de varianza, el análisis de regresión o las comparaciones múltiples, siempre y cuando se cumplan los tres supuestos o requisitos: 1) normalidad, 2) homocedasticidad e 3) independencia de los residuales. En caso de que alguno(s) de estos no se cumplan, habrá que pensar en una prueba o análisis no paramétrico equivalente.
3. ESTUDIO DE SIMULACIÓN
A continuación se presenta el planteamiento del problema, la metodología y los resultados del estudio de simulación: Robustez de un modelo de Markov de tres estados bajo distintas especificaciones distribucionales de los tiempos de transición [5].
3.1 Planteamiento del problemaEl objetivo de este estudio de simulación fue estudiar el comportamiento de las estimaciones de los parámetros de las funciones de intensidad en un modelo de Markov de tres estados en presencia de datos longitudinales, como el modelo enfermedad-muerte propuesto por Harezlak et al. [7], con una estructura de correlación markoviana de primer orden [8], cuando se viola el supuesto de exponencialidad de los tiempos de transición y se varía el tamaño muestral y máximo número de visitas. El problema se basa en un modelo como el que se presenta en la Figura 2 con funciones de intensidad dadas por
![]() (1)
(1)
donde ![]() representa la
función de intensidad no especificada paramétricamente cuando no se tienen en
cuenta covariables. La función
representa la
función de intensidad no especificada paramétricamente cuando no se tienen en
cuenta covariables. La función ![]() especifica la
forma en que la función de intensidad cambia en función de las covariables
especifica la
forma en que la función de intensidad cambia en función de las covariables ![]() . En realidad,
. En realidad, ![]() especifica el
efecto de la variable continua, y
especifica el
efecto de la variable continua, y ![]() el efecto de la
variable dicótoma.
el efecto de la
variable dicótoma.
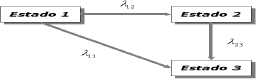
Figura 2. Modelo de tres estados con un estado absorbente (estado 3)
Figure 2.Three state model with an absorbing state
(state number 3)
Los experimentos en este caso consisten en la estimación de los parámetros del modelo presentado en (1) después de generar los posibles escenarios o tratamientos vía simulación. Para estimar dichos parámetros se usó el método de máxima verosimilitud conjuntamente con el sistema de ecuaciones hacia adelante de Kolmogorov [8]. La maximización de la función de verosimilitud se llevó a cabo por medio del Algoritmo Simplex de Nelder y Mead [9].
3.2.1 Factores
Se declararon
los siguientes tres factores. 1) Distribución.
Se utilizaron cinco distribuciones continuas y positivas para los tiempos de
transición: Exponencial, Gamma, Weibull, Lognormal y Pareto. 2) Tamaño de muestra. Se consideraron seis
tamaños muestrales: 100, 200, 400, 800, 1000 y 1500. 3) Máximo número de visitas. Los niveles de este factor fueron dos: 4
y 6. En total son 5´6´2=60 tratamientos, para cada uno de
los cuales se corrieron 1000 simulaciones.
3.2.2 Variables respuestas
Para
estudiar los efectos de la distribución de los tiempos de transición, el tamaño
muestral y el máximo número de visitas sobre la estimación de los parámetros
del modelo, se declaró como variable respuesta el sesgo relativo cuadrático. En
cada tratamiento se obtienen las estimaciones puntuales de los tres parámetros
del modelo. Dichas estimaciones corresponden a la media aritmética de las mil
simulaciones. Posteriormente se calculó el sesgo relativo de la forma
![]() (2)
(2)
donde ![]() puede ser
puede ser ![]() ,
, ![]() ó
ó ![]() . Valores cercanos a cero, indican que la estimación es
buena. Cuando el sesgo relativo es mayor que cero, se dice que el parámetro fue
sobreestimado, lo cual no es bueno; de lo contrario, se dice que fue
subestimado, lo cual tampoco es bueno. Luego, tanto valores altos como bajos
del sesgo relativo indican que las estimaciones de los parámetros no son
buenas. Una manera de mejorar la interpretación de esta variable es elevándola
al cuadrado; así, valores pequeños (cercanos a cero) del sesgo relativo al
cuadrado es indicador de buenas estimaciones, y valores altos (alejados del
cero) del sesgo relativo al cuadrado es indicador de malas estimaciones. En
la Figura 3 estudio se ilustra
el diseño del estudio.
. Valores cercanos a cero, indican que la estimación es
buena. Cuando el sesgo relativo es mayor que cero, se dice que el parámetro fue
sobreestimado, lo cual no es bueno; de lo contrario, se dice que fue
subestimado, lo cual tampoco es bueno. Luego, tanto valores altos como bajos
del sesgo relativo indican que las estimaciones de los parámetros no son
buenas. Una manera de mejorar la interpretación de esta variable es elevándola
al cuadrado; así, valores pequeños (cercanos a cero) del sesgo relativo al
cuadrado es indicador de buenas estimaciones, y valores altos (alejados del
cero) del sesgo relativo al cuadrado es indicador de malas estimaciones. En
la Figura 3 estudio se ilustra
el diseño del estudio.
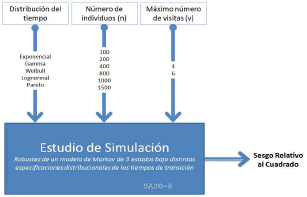
Figura 3. Diseño del estudio de simulación. Efectos
fijos de tres factores y dos bloques
Figure 3. Design of a simulation study. Two blocks and three fixed effects
![]() (3)
(3)
donde ![]() representa la media global del sesgo relativo
al cuadrado,
representa la media global del sesgo relativo
al cuadrado, ![]() el efecto del factor distribución (con i =
Exponencial, Gamma, Weibull, Lognormal y Pareto),
el efecto del factor distribución (con i =
Exponencial, Gamma, Weibull, Lognormal y Pareto), ![]() el efecto del tamaño de muestra (con j = 100,
200, 400, 800, 1000 y 1500),
el efecto del tamaño de muestra (con j = 100,
200, 400, 800, 1000 y 1500), ![]() el efecto del máximo número de visitas (con k
= 2 y 6);
el efecto del máximo número de visitas (con k
= 2 y 6); ![]() ,
, ![]() ,
, ![]() y
y ![]() corresponden a las interacciones entre los
tres factores;
corresponden a las interacciones entre los
tres factores; ![]() y
y ![]() representan el efecto de los bloques tipo de
parámetro y tipo de transición, respectivamente (con l =
representan el efecto de los bloques tipo de
parámetro y tipo de transición, respectivamente (con l = ![]() ,
, ![]() y
y ![]() , y m = 1-2, 1-3 y 2-3, respectivamente); finalmente,
, y m = 1-2, 1-3 y 2-3, respectivamente); finalmente, ![]() representa la interacción entre los bloques, y
representa la interacción entre los bloques, y ![]() el componente de error. Para todas las pruebas
se consideró un nivel de significancia de 0.05. Las simulaciones fueron
realizadas utilizando el software SAS/IML [10], y para el análisis de los datos
se usó el paquete estadístico de dominio público R [11].
el componente de error. Para todas las pruebas
se consideró un nivel de significancia de 0.05. Las simulaciones fueron
realizadas utilizando el software SAS/IML [10], y para el análisis de los datos
se usó el paquete estadístico de dominio público R [11].
Como se
mencionó previamente, un resultado del sesgo relativo cuadrático que tienda a
cero es un indicador de buenas estimaciones de los parámetros de (1). Después
de emplear el algoritmo paso a paso (hacia adelante y hacia atrás), se realizó
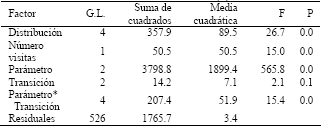
un análisis de varianza el cual se presenta en la Tabla 1. En este caso, el
intercepto representa los niveles referencia de las categorías distribución Exponencial, máximo número de visitas 4, parámetro ![]() , y transición
1 a 2.
Luego, los signos de las categorías restantes se interpretan tomando en cuenta
tales referencias. Del análisis de varianza se puede apreciar que de los tres
factores del estudio de simulación, sólo la distribución del tiempo de
transición y el número máximo de visitas resultaron significativos
(P<<0.01). Por otro lado, el bloque tipo de parámetro resultó ser
significativo explicando gran cantidad de variabilidad (P<<0.01).
Mientras tanto, pese a que el bloque tipo de transición no es significativo
(P=0.1), su interacción con el bloque tipo de parámetro sí lo es
(P<<0.01).
, y transición
1 a 2.
Luego, los signos de las categorías restantes se interpretan tomando en cuenta
tales referencias. Del análisis de varianza se puede apreciar que de los tres
factores del estudio de simulación, sólo la distribución del tiempo de
transición y el número máximo de visitas resultaron significativos
(P<<0.01). Por otro lado, el bloque tipo de parámetro resultó ser
significativo explicando gran cantidad de variabilidad (P<<0.01).
Mientras tanto, pese a que el bloque tipo de transición no es significativo
(P=0.1), su interacción con el bloque tipo de parámetro sí lo es
(P<<0.01).
Tabla 1. Análisis de varianza del modelo de efectos
del sesgo relativo cuadrático (3)
Table 1. Analysis of variance for the quadratic relative bias effect model (3)
El hecho de que bloque tipo de parámetro resultara significativo, implica que el sesgo relativo cuadrado difiere en la estimación de por lo menos uno de los tres parámetros del modelo (1). La misma interpretación se haría para los factores distribución y máximo número de visitas. Para establecer tales diferencias, en las Figuras 4 a 9 se presentan los efectos de los factores y de los bloques por medio de gráficos de cajas y bigotes con sus respectivos intervalos de confianza del 95% para la mediana del logaritmo del sesgo relativo cuadrático. A su vez, en la Tabla 2 se presentan los valores P de los niveles de los factores y de los bloques que resultaron significativos.
Tabla 2. Significancia de
los factores y de los bloques obre el sesgo relativo cuadrático
Table 2. Statistical significance of factors and
blocks on the quadratic relative bias
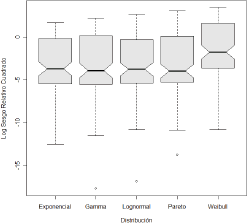
Figura 4. Efecto del factor distribución de los tiempos de transición
sobre el sesgo relativo cuadrático
Figure 4. Effect of the transition times
distribution factor on the quadratic relative bias
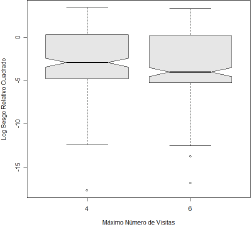
Figura 5. Efecto del factor máximo número de visitas sobre el sesgo relativo cuadrático
Figure 5. Effect of the maxim number of visits
factor on the quadratic relative bias
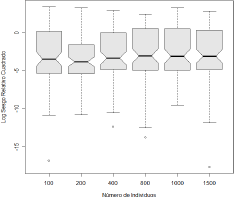
Figura 6. Efecto del factor tamaño de
muestra sobre el sesgo relativo cuadrático
Figure 6. Efect
of the sample size factor on the quadratic relative bias
En cuanto al efecto de los bloques, se
aprecian diferencias entre el tipo de parámetro a estimar. El caso más
desfavorable fue para la estimación del parámetro ![]() , cuyo sesgo relativo fue significativamente mayor al
del parámetro referencia (P<<0.0001) y al del parámetro
, cuyo sesgo relativo fue significativamente mayor al
del parámetro referencia (P<<0.0001) y al del parámetro ![]() , según el gráfico de
la Figura 7 donde se pueden
observar claramente tales diferencias.
, según el gráfico de
la Figura 7 donde se pueden
observar claramente tales diferencias.
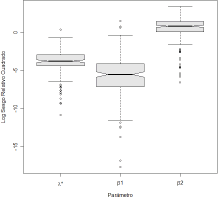
Figura 7. Efecto del
bloque tipo de parámetro sobre el sesgo relativo cuadrático
Figure 7. Efect of the parameter type block on
the quadratic relative bias
En cambio,
el comportamiento del parámetro ![]() fue el mejor,
dado que el sesgo relativo cuadrático cometido en esta estimación fue
significativamente menor (P<<0.0001). En cuanto al factor tipo de transición,
se observó que el comportamiento del sesgo relativo cuadrático fue similar en las
tres transiciones (Figura 8). Sin embargo, de
la Figura 9 se puede observar
el efecto de la interacción entre los bloques tipo de parámetro y tipo de transición
donde se aprecia que tal efecto es aportado por el parámetro
fue el mejor,
dado que el sesgo relativo cuadrático cometido en esta estimación fue
significativamente menor (P<<0.0001). En cuanto al factor tipo de transición,
se observó que el comportamiento del sesgo relativo cuadrático fue similar en las
tres transiciones (Figura 8). Sin embargo, de
la Figura 9 se puede observar
el efecto de la interacción entre los bloques tipo de parámetro y tipo de transición
donde se aprecia que tal efecto es aportado por el parámetro ![]() en las
transiciones 1-3 y 2-3, cuyo comportamiento fue diferente en los otros dos
parámetros.
en las
transiciones 1-3 y 2-3, cuyo comportamiento fue diferente en los otros dos
parámetros.
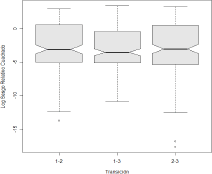
Figura 8. Efecto del bloque tipo de transición
sobre el sesgo relativo cuadrático
Figure 8. Efect
of the transition type block on the quadratic relative bias
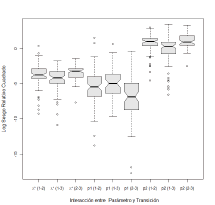
Figura 9. Efecto de la interacción entre los bloques
tipo de parámetro y tipo de transición
Figure 9. Efect
of the parameter type block transition type block interaction
En resumen, se destaca el efecto desfavorable sobre el sesgo relativo de la distribución Weibull, el efecto favorable de realizar máximo 6 visitas, y las diferencias en media del sesgo relativo cuadrático entre las estimaciones de los tres parámetros del modelo (1).
3.4 Conclusiones del estudio de simulación
4. DISCUSIÓN
Se pudo apreciar las ventajas de emplear la metodología del diseño experimental en los estudios de simulación. Al realizar el análisis de los resultados de la simulación por medio de métodos inferenciales, se pudo concluir con cierto nivel de significancia sobre los efectos que los factores ejercen sobre la variable respuesta, en este caso: logaritmo del sesgo relativo cuadrado. En muchas de las interpretaciones realizadas sobre esta variable respuesta no se enfatizó sobre la transformación logaritmo ya que al tratarse de una función monótona la interpretación es idéntica.
Al parecer,
emplear este tipo de análisis mejora la calidad de las conclusiones (siendo
éstas más contundentes) y la presentación de los resultados de los estudios de
simulación. De otro lado, considerar estudios de simulación bajo el enfoque de
diseños factoriales ![]() ,
, ![]() o fraccionados
podría llevar a pensar en estudiar muchos factores a la vez optimizando de tal
manera el tiempo que se invierte en la corrida de las simulaciones. Hasta ahora
sólo se ha comentado sobre diseños de efectos fijos, pero podría ser útil
valorar la utilización de los diseños de efectos aleatorios como un método de
identificación de posibles factores relevantes que deberían ser tenidos en
cuenta. La invitación con este manuscrito es motivar a los investigadores que
trabajan en el área de la estadística a implementar la metodología del diseño y
análisis de experimentos en los estudios de simulación; en otras palabras,
aplicar de lo que sabemos, en este tipo de análisis.
o fraccionados
podría llevar a pensar en estudiar muchos factores a la vez optimizando de tal
manera el tiempo que se invierte en la corrida de las simulaciones. Hasta ahora
sólo se ha comentado sobre diseños de efectos fijos, pero podría ser útil
valorar la utilización de los diseños de efectos aleatorios como un método de
identificación de posibles factores relevantes que deberían ser tenidos en
cuenta. La invitación con este manuscrito es motivar a los investigadores que
trabajan en el área de la estadística a implementar la metodología del diseño y
análisis de experimentos en los estudios de simulación; en otras palabras,
aplicar de lo que sabemos, en este tipo de análisis.
5. AGRADECIMIENTOS
Al Grupo Infección y Cáncer de la Universidad de Antioquia y a la Escuela de Microbiología de la misma universidad. A la Escuela de Estadística de la Universidad Nacional de Colombia, Sede Medellín.
REFERENCIAS
[1] MONTGOMERY, DOUGLAS. Design and analysis of experiments. Fifth Edition. New York: John Wiley & Sons, Inc., 1997.
[2] NETER, J; KUTNER, M; NACHTSHEIM, C; WASSERMAN, W. Applied linear statistical models. Fourth Edition. McGraw Hill, 1996.
[3] LAW, A.; KELTON, W. Simulation Modeling and Analysis. Third edition. New York: Mc Graw Hill , 2000.
[4] ROBERT, C. and CASELLA, G. Monte Carlo Statistical Methods. New York: Springer. 2004.
[5] BAENA ZAPATA, ARMANDO. Robustez de un modelo de Markov de tres estados bajo distintas especificaciones distribucionales de los tiempos de transición. [Tesis de Maestría]. Medellín: Universidad Nacional de Colombia, Sede Medellín, Escuela de Estadística, 2007.
[6] SALAZAR URIBE, JUAN CARLOS. Multi-state Markov models for longitudinal data [PhD thesis]. Lexington, KY: University of Kentucky, 2004.
[7] HAREZLAK, J., GAO, S., HUI, SL. An illness death stochastic model in the analysis of longitudinal dementia data. Statistics in Medicine. 2003, vol 22, núm. 9, p. 1465 1475.
[8] BHAT, U. NARAYAN. Elements of Applied Stochastic Processes. Second Edition. New York: John Wiley & Sons, Inc., 1984. 685.
[9] NELDER, JA AND MEAD, R. A simplex method for function maximization. The computer Journal. 1965, vol 67, p. 308 313.
[10] SAS Institute Inc. SAS IML Software: Usage and Reference. Cary, NC, USA . 1990.
[11] R Development Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. [ Vienna, Austria ]. Disponible en Web:
[12] CONOVER, W., JOHNSON, M.E., and JOHNSON, M. A comparative study of test of homogeneity of variances, with applications to the Outer Continental Shelf Bidding Data. Technometrics 23, 351-361.