



Publicado
Técnicas genéticas en la solución de un problema minero
A genetic algorithm to solve one mining selection problem
DOI:
https://doi.org/10.15446/dyna.v84n203.65566Palabras clave:
Genetic Algorithm, Mathematical Modeling, Mining, Programming (es)Genetic algorithm, mathematical modeling, mining, programming (en)
A mathematical model’s system for optimizing the efficiency for sampling exploration and exploitation networks in lateritic nickel and cobalt deposits, located in the north-eastern province of Holguin, was developed in the “Centro de Investigaciones del Níquel”. This system includes a new reservoir model based on multivariate substantial classification using the Markov model for discrete stochastic processes. As a result of the application of these models a linear optimization problem was obtained comprising an objective function, several constraints as inequalities and an additional restriction in the form of equality linked to the number of wells to be selected. The
generated problem has polynomial computational complexity and because no accurate methods exist to solve it, an automated tool that brings up feasible solutions was developed based on genetic algorithms.
Recibido: 9 de junio de 2017; Revisión recibida: 10 de octubre de 2017; Aceptado: 24 de octubre de 2017
Resumen
A partir de la decisión de automatizar la solución de un problema de optimización vinculado a la selección de una cantidad “N” de pozos de un yacimiento, que refleje las características generales estudiadas del mismo y disponiendo de los modelos matemáticos creados a tal efecto, surge la necesidad de buscar alguna alternativa que permita obtener las soluciones del problema planteado. Los modelos matemáticos creados generan un sistema formado por una función objetivo, varias restricciones en forma de desigualdades y una restricción adicional, en forma de igualdad: un problema clásico de selección. Este tipo de problema tiene soluciones de complejidad computacional no polinomial; por tal motivo, en lugar de implementar algoritmos complejos, se decidió diseñar una herramienta automatizada basada en el empleo de algoritmos genéticos. Se creó una aplicación automatizada para la solución del problema de selección de una muestra minera descrito, lográndose implementar una solución computacional de baja complejidad.
Palabras claves:
Algoritmo genético, minería, programación, yacimiento..Abstract
Based on the decision to automate the solution of an optimization problem related to the selection of an "N" number of geological exploration wells in a reservoir, which reflects the general characteristics of the well and having the mathematical models created for that purpose, arises the need to look for some alternative that allows to obtain the solutions of the raised problem. The mathematical models created generate a system formed by an objective function, several constraints in the form of inequalities and an additional restriction, in the form of equality: a classic problem of selection. This type of problem has solutions of non-polynomial computational complexity; for this reason, instead of implementing complex algorithms, it was decided to design an automated tool based on the use of genetic algorithms. An automated application was created for the solution of the problem of selection of a described mining sample, being able to implement a low complexity computational solution.
Keywords:
Genetic algorithm, mathematical modeling, mining, programming..1. Introducción
En la industria del níquel, en el oriente de Cuba, es frecuente la realización de pruebas metalúrgicas con el material extraído de los diferentes yacimientos lateríticos. Estas pruebas son realizadas con el objetivo de estimar y ajustar la recuperación metalúrgica a nivel industrial. Como el mineral empleado en estas pruebas debe ser representativo de cada uno de los yacimientos, la “industria” se formula el siguiente problema:
“Problema de selección minero”: Dados “n” pozos de la red de exploración/explotación minera, cómo seleccionar “N” de ellos que sean representativos de las características de todo el yacimiento.
Actualmente la industria del níquel cubana da respuesta a esta interrogante:
-
Utilizando métodos tradicionales basados en modelos matemáticos (sustentados por métodos geoestadísticos).
-
Utilizando el modelado Markoviano: "El modelo Markoviano" para yacimientos constituye una secuencia de cadenas de Markov [6], que genera un sistema de matrices de transferencia, cada una de las cuales se corresponde con una dirección en el yacimiento sobre la red de exploración, se construye sucesivamente de un pozo de la red de exploración al inmediato y también a saltos. Los eventos que se modelan constituyen clases de comportamientos en el yacimiento; las matrices de transferencias contienen las probabilidades con que puede aparecer una clase en un punto, dada la ocurrencia de otra en el punto que se considera inmediato anterior, se apoya en una función de georeferencia para construir las distribuciones probabilísticas de las clases sobre el yacimiento” [5].
En el proceso de modelado de los yacimientos y en la construcción de su “Modelo Markoviano” son empleadas varias herramientas automatizadas; entre ellas la denominada SWORE (desarrollada por investigadores del Centro de Investigación del Níquel (CEDINIQ) que, en base a algoritmos de alta complejidad paralelizados para disminuir su tiempo de corrida, produce los coeficientes del siguiente modelo lineal binario:
Función objetivo:

Restricciones:



Las ecuaciones (1), (2) y (3) pueden escribirse en forma vectorial de la siguiente manera:
Función objetivo:

Restricciones:
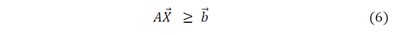

Debido a que las variables Xj (j= 1..n) sólo toman valores cero o uno (son variables binarias), el problema no puede ser resuelto directamente con el empleo del conocido método SIMPLEX de la “Investigación de Operaciones”. Surge entonces la necesidad de emplear otras técnicas de optimización y por tanto investigar cómo solucionar este problema.
2. Materiales y métodos
Este trabajo investigativo parte de la necesidad de resolver un problema concreto surgido de otras investigaciones en el campo de la modelación matemática de problemas mineros: “el problema de selección minero” descrito anteriormente. Se desarrolló una búsqueda bibliográfica sobre el tema y en especial sobre la técnica de los algoritmos genéticos y sus aplicaciones.
2.1. Motivación
La investigación comenzó intentando responder una pregunta muy simple: cuál es la magnitud del problema a que nos enfrentamos(. Para brindar una idea clara formulemos un posible problema de selección de pozos mineros de forma muy concreta: “Se dispone de abundante información geoquímica y geofísica de cada uno de los 1500 pozos perforados en una red del yacimiento “Y” y se desea seleccionar 10 pozos que sean representativos de las características medidas del yacimiento, con el objetivo de realizar una prueba metalúrgica que aporte información sobre la eficiencia de extracción de níquel y cobalto en la industria operando con mineral proveniente del yacimiento “Y”.
Aunque no es nuestra intención detallar todo el proceso, es bueno aclarar que la cantidad de pozos a seleccionar no debe ser muy pequeña, porque se afectaría la representatividad de la muestra y tampoco puede ser muy grande por el impacto económico de la prueba.
La cantidad de formas en que podemos seleccionar 10 pozos de una red formada por 1500 es 15420310928028700000000000. Imagine qué tiempo le tomaría a una computadora personal evaluar cada una de esas posibles soluciones en cada una de las “m” restricciones del modelo lineal binario propuesto para determinar cuáles las satisfacen e ir evaluándolas en la función objetivo para tomar la que maximiza su valor.
La Tabla 1 ilustra la magnitud de las cantidades de soluciones a evaluar a partir de la cantidad de pozos estudiados en las redes del yacimiento y asume que se pretenden seleccionar 10 pozos representativos del yacimiento (“N” = 10):
Fuente: Elaboración propiaTabla 1: Relación “Cantidad de pozos - formas de seleccionar grupos de 10 pozos”

El gráfico mostrado en la Fig. 1, confeccionado con datos de la Tabla 1 brinda una mejor idea de la magnitud del problema a resolver, ya que permite apreciar cómo se dispara la cantidad de soluciones a evaluar al incrementar la cantidad de pozos de 30 a 100 (Fig. 1):

Figura 1: Relación cantidad de pozos - soluciones posibles (N=10).
Un estimado del tiempo que tardaría una computadora personal aceptable actualmente aportó el increíble resultado de unos cuantos años. Indiscutiblemente hay que buscar una alternativa diferente para resolver el problema planteado. La Fig. 2 resume varios métodos empleados en la solución de problemas de este tipo:

Figura 2: Esquema básico de un algoritmo genético (Salazar y Sarzuri, 2015).
Tras rechazar el empleo de algunos métodos determinísticos y otros probabilísticos, algunos de forma práctica y otros de forma teórica, surge la idea de incursionar en el mundo de los algoritmos genéticos con el desarrollo de una aplicación para resolver el problema de programación lineal binaria.
Dado que gran parte de los problemas prácticos que se necesitan resolver son de los denominados NP-hard, los algoritmos heurísticos o de aproximación desempeñan un papel importante en la resolución de problemas de optimización discreta con la idea de encontrar buenas soluciones factibles de manera rápida [8].
2.2. Los algoritmos genéticos
Un algoritmo genético (AG) es una técnica de optimización y búsqueda basada en los principios de la genética y la selección natural. Un AG permite que una población compuesta de muchos individuos evolucione bajo reglas de selección específicas a un estado que maximice o minimice la adaptabilidad [2].
“Un algoritmo genético, desde el punto de vista de la optimización, es un método poblacional de búsqueda dirigida basada en probabilidad. Bajo una condición muy débil (que el algoritmo mantenga elitismo, es decir, guarde
siempre al mejor elemento de la población sin hacerle ningún cambio), se puede demostrar que el algoritmo converge en probabilidad al óptimo” [4].
“La terminología del algoritmo genético tiene una mezcla de términos naturales y artificiales. El conjunto de posibles soluciones se llama población. La población inicial evoluciona de generación en generación. Cada individuo de la población se llama cromosoma y cada código presente en el cromosoma se conoce como gen (el cromosoma es una cadena de genes)” [7].
Este esquema muestra los operadores genéticos básicos: Cruzamiento, mutación y selección correspondientes a procesos observados en los seres vivos: reproducción, mutación (cambios aleatorios no explicados en uno o varios individuos) y la selección natural. Cada uno de estos operadores, descritos por Rincón [6], puede ser concebido de diferentes formas, dando lugar a diversas variantes; por sólo citar un ejemplo: entre los métodos de selección clásicos se encuentran: la selección por ruleta, por torneo, etc.
Zbigniew [9] realiza una interesante descripción de qué son los algoritmos genéticos, cómo trabajan y por qué funcionan [9]. Mientras que en el capítulo catorce de Practical Optimization [1] podrá descubrir los secretos de los operadores genéticos básicos y algunas de las ventajas de los algoritmos genéticos entre ellas: la de trabajar con la solución completa y la facilidad de su implementación computacional.
2.3. Propuesta de algoritmo genético
El problema planteado y la ecuación (3) del modelo lineal binario desarrollado sugieren de forma natural la siguiente codificación para la creación de un algoritmo genético:
-
Cromosoma o individuo: cualquier vector binario
 .
. -
Gen: cualquier componente del vector binario; por ejemplo:

En esta codificación un individuo representa exactamente una de las posibles formas de seleccionar un subconjunto de “N” pozos representativos de las características estudiadas en los “n” pozos del yacimiento: una combinación de pozos candidata; mientras que cada gen (de un individuo) representa la pertenencia o no de cada pozo del yacimiento al subconjunto de “N” pozos representativos de las características del yacimiento.
En esta codificación un individuo representa exactamente una de las posibles formas de seleccionar un subconjunto de “N” pozos representativos de las características estudiadas en los “n” pozos del yacimiento: una combinación de pozos candidata; mientras que cada gen (de un individuo) representa la pertenencia o no de cada pozo del yacimiento al subconjunto de “N” pozos representativos de las características del yacimiento.
Ejemplo #1: Supongamos que se estudia un yacimiento en busca de níquel, cobalto y manganeso. Para este estudio han sido perforados y analizados 1000 pozos (P1, P2, P3,…, P1000) deseándose obtener un subconjunto de 8 pozos representativos del yacimiento con vista a la realización de una prueba metalúrgica. Aquí la cantidad de combinaciones posibles es:

El vector (1,1,1,1,1,1,1,1,0,0,…0), con los 8 primeros componentes en uno y el resto en cero, representa la hipótesis: 8 primeros pozos (P1, P2, P3,…, P8) son representativos de las características estudiadas del yacimiento.
Análogamente el vector (0,0,…0,1,1,1,1,1,1,1,1), con 992 ceros al inicio y 8 unos al final, corresponde a la hipótesis
de que los 8 últimos pozos del yacimiento (P993, P994, P995,…, P1000) son representativos del yacimiento.
Como hemos calculado en (8) tenemos 24115080524699400000 posibles combinaciones; en términos genéticos: una población de 24115080524699400000 individuos de los que deberíamos elegir el mejor adaptado a su entorno (el que cumpla con los requisitos exigidos: restricciones (6), (7) y (4) maximizando la función objetivo (5)). Lo que antes llamamos función objetivo en el modelo pasa a ser la función de adaptabilidad o “fitness” en el modelo genético.
Es conocido que todos los algoritmos genéticos son diferentes pero comparten una idea central, mostrada en la Fig. 3, basada en generar aleatoriamente una población inicial de individuos y aplicarle operadores genéticos para obtener una nueva población, manteniendo con una probabilidad conocida los mejores individuos de la generación anterior.

Figura 3: Pantalla principal de la aplicación. Fuente: Elaboración propia.
La población inicial puede ser obtenida por diversos métodos. Una clasificación interesante es definida teniendo
en cuenta si se emplea o no información acerca del problema que se intenta resolver. En el ejemplo #1 a la población inicial podría ser generada por ejemplo:
-
Asignado unos y ceros aleatoriamente a las componentes de vectores de orden 1000 (sin conocimiento alguno del problema).
-
Construyendo vectores de orden 100 con exactamente 8 componentes en uno (haciendo uso de la restricción (7) del modelo binario en forma vectorial) y el resto en cero.
En el algoritmo y aplicación objetos de este artículo fueron concebidos a partir de las ideas básicas de los algoritmos genéticos por lo que heredan su esquema básico.
La población inicial es construida con vectores generados aleatoriamente con una probabilidad conocida de obtener un vector que satisfaga la restricción (7) con el objetivo de mejorar controladamente la población inicial.
Antes de elegir este método de generación de la población inicial se analizaron las siguientes variantes:
-
Generar aleatoriamente la población. La ventaja de esta variante está dada por la diversidad de la población inicial, pero tiene la desventaja de un bajo elitismo de sus individuos, pues no garantizan el cumplimiento de la restricción más sencilla: la restricción (7).
-
Generar una población inicial que satisfaga la restricción de la cantidad de pozos a seleccionar. Esto es posible dado que la evaluación de la restricción (7) es extremadamente menos costosa que la evaluación de las restricciones (6). Esta variante incrementa notoriamente el elitismo de los individuos de la población, pues todos sus miembros ya satisfacen una de las restricciones del problema, pero simultáneamente, provoca que la siguiente generación de individuos (después de un proceso de reproducción o cruce) sea menos elitista que la de sus ancestros. Esta pérdida de elitismo viene dada porque, en la práctica, “N” es mucho menor que “n” y por tanto, los cromosomas de cada individuo tienen muchos genes con valor cero; por tal motivo los operadores de cruces genéticos clásicos tienden, en estos casos, a eliminar los genes en uno.
-
La variante hibrida o intermedia entre las dos anteriores elimina en cierta medida las desventajas de cada una de ellas, pero adiciona la complejidad de la elección adecuada del balance entre pozos que satisfacen la restricción (7) y pozos que no la satisfacen. Este equilibrio fue determinado de forma experimental y se piensa ajustar automáticamente según los resultados de cada corrida de la aplicación.
Como función de adaptabilidad se escogió la propia función objetivo ajustada con algunos pesos determinados en base a factibilidad de cumplimiento de cada una de las “m” restricciones descritas en (2). Estos pesos son generados a partir de un ordenamiento ascendente de los sumandos en cada restricción y la cantidad de X j en uno necesarios para satisfacer cada restricción.
La reproducción fue planificada por el método clásico de un corte simple de genes pero con elección aleatoria del punto de corte para evitar la pérdida de diversidad de la población que este método genera en segundos descendientes. La introducción de un corte aleatorio hace que las nuevas generaciones tengan una probabilidad mayor de ser no homogéneas y por tanto incrementa la posibilidad de que el método continúe trabajando en busca del individuo óptimo. Adicionalmente el algoritmo propuesto incluye un operador genético denominado BigBang que es equivalente a generar una población inicial nueva y cuya ejecución es parametrizable, siendo recomendable su ajuste en base a la cantidad de ejecuciones del operador de reproducción y el de mutación empleados (la aplicación desarrollada brinda valores por defecto para cada parámetro configurable, pero permite su variación y afinamiento para problemas específicos).
El operador de mutación es el encargado, al igual que en la naturaleza, de mantener la diversidad de la población y generar individuos “atípicos”, pero es importante no abuzar de él, porque su incremento implica un aumento de la aleatoriedad de la población. De incrementarse excesivamente la frecuencia de las mutaciones, el algoritmo genético se convertiría en un algoritmo de búsqueda aleatoria de soluciones.
El proceso de selección de los mejores individuos ha sido desarrollado a partir del método clásico de selección por torneo, dividiendo la población generada por la reproducción (algunas ocasiones mutada) en dos grupos y enfrentando a cada individuo de un grupo con uno del otro en pequeños torneos. En este operador genético desarrollado, no siempre tomamos el mejor individuo en cada torneo (algo que parece una contradicción con la ideabásica de método genético, pero que mantiene la diversidad en la población). En esta variante de solución genética se ha introducido un coeficiente de probabilidad para la elección del mejor individuo en cada pequeño torneo; naturalmente si acercamos este coeficiente a cero, estaremos bajando la probabilidad de mejorar cualitativamente la población y si lo acercamos mucho a uno, estaremos disminuyendo la calidad de la población. Adicionalmente se ha introducido un coeficiente, denominado coeficiente de remplazo, para garantizar un mínimo de aleatoriedad en cada nueva generación obtenida por este algoritmo genético.
Es importante mantener la diversidad de la población porque, por ejemplo: el cruce de dos individuos de poca aptitud (bajo valor de la función de aptitud y por tanto individuos que no constituyen un óptimo en el problema minero), puede generar un nuevo individuo con mejor aptitud; sabemos que la naturaleza es sabia y ha probado la eficiencia de sus métodos.
Aunque es conocido que algunas herramientas que emplean actualmente métodos genéticos de solución, finalizan generalmente al dejar de encontrar soluciones, al disminuir la frecuencia de sus hallazgos o al alcanzar un umbral prefijado de la función de aptitud; el algoritmo desarrollado finaliza por tiempo de corrida dada la magnitud de la población total y la simplicidad computacional de su implementación.
3. Resultados y discusión
Se desarrolla una aplicación para la solución del “problema minero” descrito al inicio, la cual fue modelada según el paradigma de la orientación a objetos y programada en lenguaje C# empleándose algunas características de este lenguaje orientadas al paralelismo. La Fig. 4 muestra la pantalla de configuración de la aplicación para su corrida:
-
En color rojo se han destacado los parámetros a fijar comúnmente para las corridas: la cantidad de pozos a seleccionar, la ubicación del fichero con los datos a procesar y la duración máxima para la corrida en minutos, horas o días.
-
En color negro aparecen algunos parámetros que rigen el comportamiento del algoritmo genético implementado: tamaño de la población, coeficiente de remplazo, coeficiente de mutación y coeficiente BigBang. Los valores por defecto se consideran adecuados para problemas de selección de hasta un 10% en yacimientos con redes de hasta 2000 pozos.

Figura 4: Pantalla de configuración de la aplicación.
Fuente: Elaboración propia.
La aplicación es capaz de detectar, como se muestra en la Fig. 5 soluciones triviales; esto significa que antes de iniciar la corrida del algoritmo genético se realizan un conjunto de validaciones de los datos y un análisis de soluciones triviales del problema.

Figura 5: Pantalla de resultados o salida de la aplicación.
La solución mostrada tiene dos componentes:
-
Zopt(X) ( Valor de la función de aptitud que puede ser útil para comparar la calidad soluciones aportadas por corridas diferentes de la aplicación.
-
Vector X ( El mejor individuo encontrado en el tiempo de corrida prefijado. La representación de este vector binario sólo incluye sus componentes con valor uno, por lo que puede interpretarse como el listado de pozos seleccionados; por ejemplo, en la corrida cuyo resultado se muestra en la Fig. 4, los pozos a minar para la extracción de mineral destinado a la prueba metalúrgica son los siguientes: 2943, 2944, etc.
4. Conclusiones
Se ha desarrollado un algoritmo y una aplicación automatizada para la solución del problema de selección de una muestra minera para una prueba metalúrgica descrito, en base a principios genéticos y de selección presentes en la naturaleza. Se logra implementar una solución a un problema de gran complejidad computacional empleando un método de solución no exacto, pero de convergencia teórica garantizada, que ha sido automatizado de forma tal que puede emplearse en ordenadores personales.
A pesar de la complejidad computacional, con este trabajo se logra automatizar la última etapa del modelado de yacimientos mineros para la industria cubana del níquel elaborado por investigadores del Centro de Investigación del Níquel y el Instituto Superior Minero Metalúrgico de Moa, siguiendo una clasificación sustancial multivariada y con el empleo del modelo de Márkov para procesos estocásticos discretos.
El trabajo puede perfeccionarse con el empleo de técnicas de aprendizaje de forma tal que el algoritmo se auto ajuste manejando metadatos de cada corrida: un tema abierto para futuras investigaciones.
Bibliografía
Referencias
Chinneck, J., Practical optimization: A gentle introduction [online]. [Consulted July 3 of 2015]. Available at: http://www.sce.carleton.ca/faculty/chinneck/po.html
Haupt, L. and Haupt, S.E., Practical genetics algorithms. 2da. ed. New Jersey: John Wiley & Sons, Inc. 2004.
López, J., Optimización multi-objetivo. Aplicaciones a problemas del mundo real. Tesis de Doctorado, Universidad Nacional de La Plata, Argentina, 2013.
Melián-Batista, B., Moreno-Pépez, J.A. y Moreno-Vega, J.M., Algoritmos genéticos. Una visión práctica. 71. 2009. [en línea]. [Consultado: 10 de junio 2015]. Disponible en: http://www.sinewton.org/numeros/numeros/71/Darwin_03.pdf
Peña-Abreu, R.E. y Sampalanco, C.M., Optimización del muestreo tecnológico en yacimientos lateríticos cubanos. Ciencias de la Tierra y el Espacio, 14, pp. 38-50, 2013.
Rincón, J.C., Aplicación de los algoritmos genéticos en la optimización del sistema de abastecimiento de agua de Barquisimento-Cabudare. Avances en Recursos Hidraulicos [En línea], 14, 2006. [Consultado 10 de junio 2015]. Disponible en: http://www.revistas.unal.edu.co/index.php/%20arh/article/viewFile/9328/9972
Salazar-Horning, E. y Sarzuri-Guarachi, R.A. Algoritmo genético mejorado para la minimización de la tardanza total en un flowshop flexible con tiempos de preparación dependientes de la secuencia. Ingeniare. Revista Chilena de Ingeniería [En línea], 23. 2015. [Consultado 10 de junio 2015]. Disponible en: http://www.scielo.cl/pdf/ingeniare/v23n1/art14.pdf.
Vidal-Esmorís, A., 2013. Algoritmos heurísticos en optimización. Tesis de Maestría, Universidad de Santiago de Compostela, España.
Zbigniew, M., Genetic Algorithms+ data Structures = Evolution Programs, Berlin, Springer-Verlag.1996.
Cómo citar
IEEE
ACM
ACS
APA
ABNT
Chicago
Harvard
MLA
Turabian
Vancouver
Descargar cita
Licencia
Derechos de autor 2017 DYNA

Esta obra está bajo una licencia internacional Creative Commons Atribución-NoComercial-SinDerivadas 4.0.
El autor o autores de un artículo aceptado para publicación en cualquiera de las revistas editadas por la facultad de Minas cederán la totalidad de los derechos patrimoniales a la Universidad Nacional de Colombia de manera gratuita, dentro de los cuáles se incluyen: el derecho a editar, publicar, reproducir y distribuir tanto en medios impresos como digitales, además de incluir en artículo en índices internacionales y/o bases de datos, de igual manera, se faculta a la editorial para utilizar las imágenes, tablas y/o cualquier material gráfico presentado en el artículo para el diseño de carátulas o posters de la misma revista.













